
Temeljna i konstruktivna diskusija kroz 5 tačaka, o tome šta koči AI/ML projekte.
Autor: Darko Marinković
VentureBeat: “87% of AI projects will never make it into production”
Gartner: “Through 2021, 80% of AI projects will remain alchemy, run by wizards whose talents will not scale in the organization”
Slični rezultati se očekuju i od istraživanja provedenih u 2022. godini. A zašto je to tako?
1. „Ganjamo komarca macolom“
Imajući u vidu popularnost AI/ML tehnologija, koja se nerijetko karakteriše i kao „AI hype“, često se dešava da se unaprijed klijentu obeća „svemirski brod“ koji će biti izgrađen koristeći posljednje state-of-the-art algoritme koji se vrte na klasteru od n računara namijenjenih za distribuiranu obradu podataka. U realnosti se dogodi da klijent zapravo dostavi fajl sa podacima veličine 124 MB sa problemom koji je rješiv logističkom regresijom.
Prije svega, ne treba bježati od jednostavnih i provjerenih rješenja. Ne mora značiti da će biti iskorišćena kao konačno rješenje, ali mogu pokazati svoje prednosti i mane, a svi zajedno naučiti nešto iz pokušaja primjene. A na kraju krajeva, možda su i dovoljna za neke od njih. Takođe, korišćenje posljednjih postignuća u AI/ML svijetu, u smislu algoritama, ne mora biti garancija za bilo šta ukoliko imate podatke iz kojih se ne može izvući ništa zbog svog (ne)kvaliteta ili (ne)sistematičnosti. Tipičan primjer za to su labele (zavisne varijable). Ukoliko je neka pojava, označena u podacima na nesistematičan način (odnosno, postoji više izuzetaka nego pravila), teško će bilo kakav algoritam tu vrstu (ne)pravilnosti „uhvatiti“.
I na kraju hardver. Jasno je da je upotreba specijalizovanog hardvera neizbježna u većini primjena. Međutim, treba krenuti od klijenta, odnosno od resursa koje planira iskoristiti u projektu, upoznati ga sa prednostima i nedostacima istih i na kraju dimenzionisati rješenje u skladu s tim.
2. Metrike AI/ML modela nemaju vezu sa metrikama poslovnog problema
Ovdje govorimo o situacijama gdje ne postoji dovoljno saradnje Data Scientist-a i domenskih stručnjaka. Postoje dva podtipa situacija:
- Data Scientist je ekspert i za poslovni problem koji se rješava
- Domenski stučnjak je ekspert i za Data Science
U principu se ne zna koja situacija je gora, odnosno koji projekat će brže propasti.
Data Scientist teško može biti stručnjak za sve moguće domene rada koje će sresti u svom radu i zato je neophodna saradnja sa domenskim stručnjacima. Takođe, ako je Data Scientist dobro shvatio poslovni problem, od vitalnog značaja je odabrati adekvatnu tehniku rješavanja problema koja će dovesti u vezu metrike ML modela sa metrikama poslovnog problema. Ukoliko se ta veza održi od „proof of concept“ etape rada do „staging“ etape (pri čemu „staging“ etapa uključuje izlazak iz laboratorijskih uslova rada, odnosno realan tok podataka), onda smo uspjeli nešto riješiti. Data Scientist jednostavno ne smije donositi ključne odluke tokom razvoja modela bez saradnje sa domenskim stručnjacima. Takođe, domenski stručnjak mora da razumije način na koji se rješava problem i u tome će mu pomoći Data Scientist kroz „model explainability“ koncepte, a sve sa ciljem da se na kraju ne isporuči „black box“.
Drugi tip situacije nastaje kada domenski stručnjak, ohrabren činjenicom da zna napraviti pivot tabelu u Excel-u ili napisati SQL upit „od tri reda“, ubijedi sebe i sve oko sebe da je Data Scientist. Daljnji komentar nije potreban.
3. „Savršeni“ podaci
Ovdje govorimo o situacijama kada su podaci koje koristimo „savršeni“, odnosno kada pojedinici tvrde da u podacima nema ni jedna greška i da samim tim i AI/ML model mora takođe biti savršen. Podaci nikada nisu savršeni i mogu samo biti dobri za neku vrstu upotrebe, dok su veoma rijetke situacije u kojima su u originalnoj formi adekvatni i za rješavanje nekog problema koji se koristi AI/ML tehnikama. Potrebno je uvijek malo kreativnosti da se od postojećih podataka transformacijom ili dopunom dođe do podataka koji su dobri za rješavanje AI/ML problema. Kruže glasine da je to više neka vrsta umjetnosti nego egzaktna nauka.
4. Zanemarivanje eksperimentalne prirode AI/ML projekata
Ovdje govorimo o situacijama u kojima se AI/ML projekat tretira kao projekat razvoja softvera. Specifičnost AI/ML projekata je u tome što gotovo uvijek kreće od „praznog lista papira“. Naime, ni jedan problem nije isti kao onaj prošli niti postoje uopšte dva ista problema koja se rješavaju na isti način. Dakle, neophodno je postojanje eksperimentalne faze, u kojoj je cilj suziti spektar tehnika i alata kojima će se pokušati riješiti problem. Ta faza UVIJEK podrazumijeva učenje neke nove tehnike ili principa rada nekog alata s kojim će se pokušati kreirati rješenje. Dakle, nije moguće ući u projekat „potpuno spreman“.
Na kraju krajeva, skup tehnika i alata u AI svijetu se toliko brzo mijenja i evoluira, da je potpuno nemoguće reći da je neki alat ili tehnika „100% dobar“ za rješavanje nekog poslovnog problema, jer će se situacija u narednih nekoliko dana/mjeseci potpuno promijeniti. I, šta uopšte znači to kada se kaže da je nešto „100% dobro“? U AI/ML svijetu, u toku razvoja se garantuje samo da će se nešto pokušati riješiti, dok će sprega koda, podataka i modela, kroz razne vrste metrika, reći koliko smo dobri u onome što radimo i koliko smo blizu da rješenjem utičemo na poslovne metrike.
5. „Model je u produkciji – završili smo!“
Uloženo je mnogo resursa u razvoj modela u laboratorijskim uslovima i došlo se do zaključka da model ima F1 score 0.92 na izdvojenom test skupu podataka i svi su veoma srećni i zadovoljni urađenim, odnosno, „završenim“ poslom. Ostaje samo da se uradi deployment modela (staging ili production okruženje, svejedno). Nakon toga stižu informacije da model uopšte ne radi ono što treba da radi.
Šta je krenulo po zlu?
Moguće je više stvari, na primjer:
- Podaci korišćeni za treniranje su različiti od produkcionih. Realno, ni jedna pojava na svijetu nije fiksnog karaktera, pa ni podaci koji ih opisuju. Mora postojati strategija koja će uzeti u obzir činjenicu da su se podaci u međuvremenu promijenili, s ciljem da se adaptiramo (kontinuirano učenje)
- Priprema podataka za treniranje u laboratorijskim uslovima (training data pipeline) se razlikuje od pripreme produkcionih podataka (production data pipeline). U laboratorijskim uslovima podaci su nerijetko „previše dobri“ i ne oslikavaju realan tok podataka, koji može zahtijevati dodatne obradne korake da se dovedu na nivo kvaliteta u laboratorijskim uslovima.
- Podaci koji se koriste za treniranje nisu reprezantativni za pojavu koja se modelira. U praksi se teorija uzorkovanja zanemaruje prilikom selekcije skupa za treniranje, odnosno očekuje se da će prost slučajan uzorak magično proraditi u konkretnoj primjeni.
Pristup radu na AI/ML projektima, odnosno projektima koji uključuju i tu komponentu, mora biti zasnovan na iskustvu i dobrim praksama koje se primjenjuju u svijetu. Sada u igri nije samo kod, nego se mora misliti i o kodu, i o podacima, i o modelima, i o objašnjivosti modela (model explainability). A u posljednje vrijeme sve više je bitan pojam model fairness (što samo naglašava važnost korišćenja teorije uzorkovanja u izradi modela). Dakle, nije važan samo kod, nego i šta taj kod uradi sa podacima, kakav to efekat ima na model (metrike modela i metrike poslovnog problema) i koliko je to transparentno za krajnjeg korisnika rezultata modela (i koliko je to fer za neku podgrupu populacije od interesa). Kada se to pogleda kroz naočale razvojnog tima, imajući u vidu eksperimentalnu prirodu AI/ML projekata, od vitalnog je značaja postojanje verzionisanja gore pomenutih elemenata, s ciljem da svaki član tima može da vidi i da ponovo reprodukuje postignute rezultate ili da nauči nešto iz toga.
Posmatrajući gornje elemente iz produkcionog konteksta, veoma je važno imati način logovanja kvaliteta rezultata modela koji je u produkciji, što iz razloga detektovanja degradacije istih (jer ni jedan model neće vječno raditi sa istim nivoom kvaliteta), što iz razloga upoređivanja metrika kvaliteta staging i produkcionog modela.
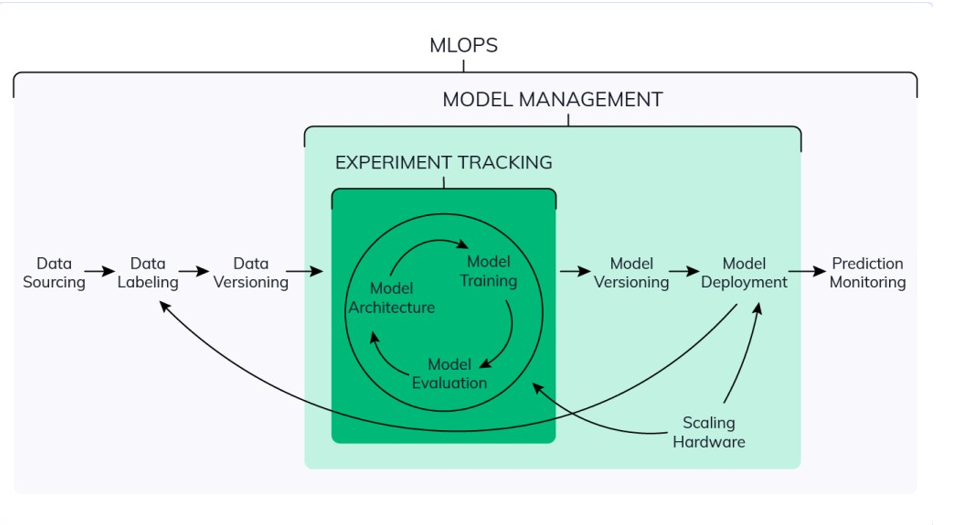
MLOps koncept
Zarad povećanja efikasnosti i minimiziranja svih potencijalnih, gore pomenutih, problema, u AI/ML sektoru kompanije Lanaco radi se na primjeni MLOps koncepta. U pitanju skup dobrih praksi za saradnju i komunikaciju između Data Scientist-a i stručnjaka za operacije. Primjena ovih praksi pojednostavljuje proces upravljanja gore navedenim elementima i automatizuje primjene modela mašinskog učenja i dubokog učenja u velikim produkcionim okruženjima. Poštujući principe MLOps koncepta, lakše je uskladiti rad modela sa poslovnim potrebama klijenta, kao i potencijalnim regulatornim zahtjevima.
Source: https://neptune.ai/blog/mlops